Mixture of Agents part 1
- 6 minutes read - 1194 wordsHow Mixture-of-Agents Enhances Large Language Model Capabilities
Introduction
In recent years, Large Language Models (LLMs) have significantly advanced the field of natural language understanding and generation. These models, pre-trained on vast datasets and fine-tuned to align with human preferences, have demonstrated impressive capabilities. However, the rapid growth in the number of LLMs and their diverse strengths has presented a new challenge: how to effectively harness the collective expertise of multiple LLMs. This is where the Mixture-of-Agents (MoA) methodology comes into play, offering a promising solution to enhance the capabilities of LLMs through collaboration.
In a significant leap forward for AI, Together AI has introduced an innovative Mixture of Agents (MoA) approach, Together MoA. This new model harnesses the collective strengths of multiple large language models (LLMs) to enhance state-of-the-art quality and performance, setting new benchmarks in AI.
Understanding the Mixture-of-Agents (MoA) Methodology
Definition and Concept
The Mixture-of-Agents (MoA) methodology is an innovative approach that leverages the strengths of multiple LLMs to enhance overall performance. Unlike traditional single-model approaches, MoA constructs a layered architecture where each layer consists of multiple LLM agents. Each agent processes the outputs from the previous layer’s agents as auxiliary information, iteratively refining the responses. This collaborative framework allows MoA to achieve state-of-the-art performance by combining the diverse capabilities of different LLMs.
How MoA Differs from Traditional Approaches
Traditional LLM approaches typically involve a single model trained on extensive data to handle various tasks. While effective, these models face limitations in scalability and specialization. Scaling up a single model is costly and time-consuming, often requiring retraining on massive datasets. In contrast, MoA capitalizes on the inherent strengths of multiple LLMs, distributing tasks among specialized agents and iteratively refining their outputs. This not only improves performance but also offers a cost-effective and scalable solution.
The Collaborativeness of LLMs
Concept of Collaborativeness in LLMs
A key insight driving the MoA methodology is the concept of collaborativeness among LLMs. This refers to the phenomenon where LLMs generate better responses when they can reference outputs from other models. This collaborativeness is evident even when the auxiliary responses are of lower quality than what an individual LLM could produce independently. By leveraging this phenomenon, MoA enhances the overall response quality through iterative refinement and synthesis.
Benefits of Collaborative LLM Responses
The collaborativeness of LLMs offers several benefits. Firstly, it allows for the integration of diverse perspectives and strengths, leading to more robust and comprehensive responses. Secondly, it mitigates the limitations of individual models, as the collective expertise can cover a broader range of tasks and scenarios. Lastly, this collaborative approach improves the adaptability and flexibility of LLMs, enabling them to handle complex and varied inputs more effectively.
Detailed Structure of the Mixture-of-Agents
Layered Architecture
MoA employs a layered architecture, with each layer comprising several LLM agents. These agents utilize outputs from the previous layer as auxiliary information to generate refined responses. This method allows MoA to integrate diverse capabilities and insights from various models, resulting in a more robust and versatile combined model. The implementation has proven successful, achieving a remarkable score of 65.1% on the AlpacaEval 2.0 benchmark, surpassing the previous leader, GPT-4o, which scored 57.5%.
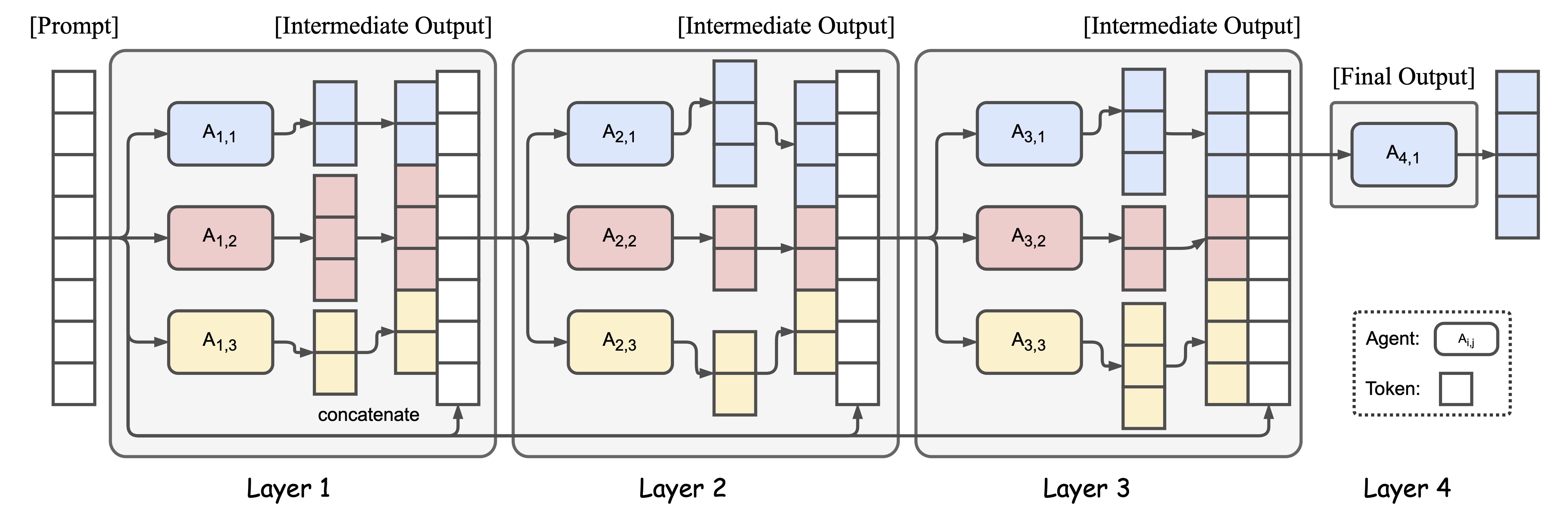
The Role of Proposers and Aggregators in MoA
A critical insight driving the development of MoA is the concept of “collaborativeness” among LLMs. This phenomenon suggests that an LLM tends to generate better responses when presented with outputs from other models, even if those models are less capable. By leveraging this insight, MoA’s architecture categorizes models into “proposers” and “aggregators.” Proposers generate initial reference responses, offering nuanced and diverse perspectives, while aggregators synthesize these responses into high-quality outputs. This iterative process continues through several layers until a comprehensive and refined response is achieved.
Performance Metrics and Benchmarking
Benchmarking Results
The Together MoA framework has been rigorously tested on multiple benchmarks, including AlpacaEval 2.0, MT-Bench, and FLASK. The results are impressive, with Together MoA achieving top positions on the AlpacaEval 2.0 and MT-Bench leaderboards. Notably, on AlpacaEval 2.0, Together MoA achieved a 7.6% absolute improvement margin from 57.5% (GPT-4o) to 65.1% using only open-source models. This demonstrates the model’s superior performance compared to closed-source alternatives.
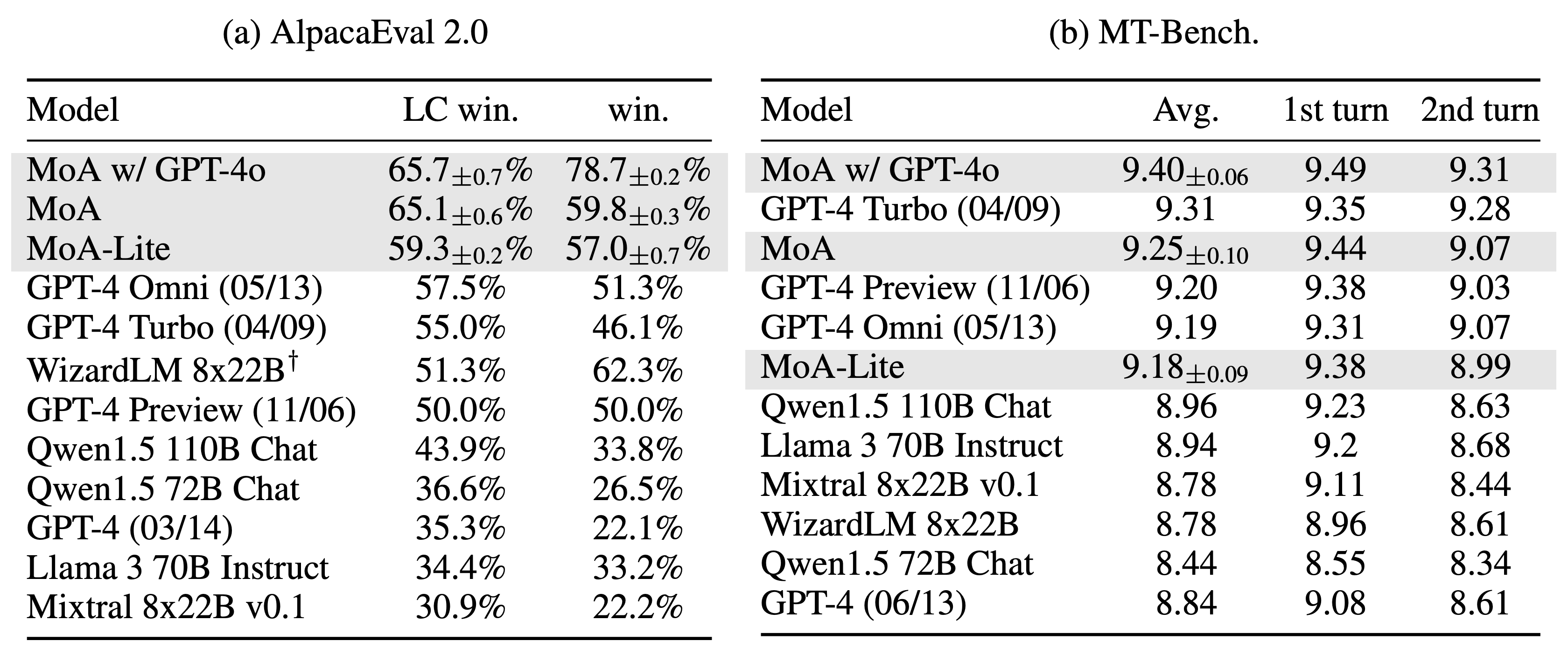
State-of-the-Art Performance and Cost-Effectiveness
In addition to its technical success, Together MoA is designed with cost-effectiveness in mind. By analyzing the cost-performance trade-offs, the research indicates that the Together MoA configuration provides the best balance, offering high-quality results at a reasonable cost. This is particularly evident in the Together MoA-Lite configuration, which, despite having fewer layers, matches GPT-4o in cost while achieving superior quality.
Broader Impact and Applications
Contributions from the Open-Source AI Community
MoA’s success is attributed to the collaborative efforts of several organizations in the open-source AI community, including Meta AI, Mistral AI, Microsoft, Alibaba Cloud, and Databricks. Their contributions to developing models like Meta Llama 3, Mixtral, WizardLM, Qwen, and DBRX have been instrumental in this achievement. Additionally, benchmarks like AlpacaEval, MT-Bench, and FLASK, developed by Tatsu Labs, LMSYS, and KAIST AI, played a crucial role in evaluating MoA’s performance.
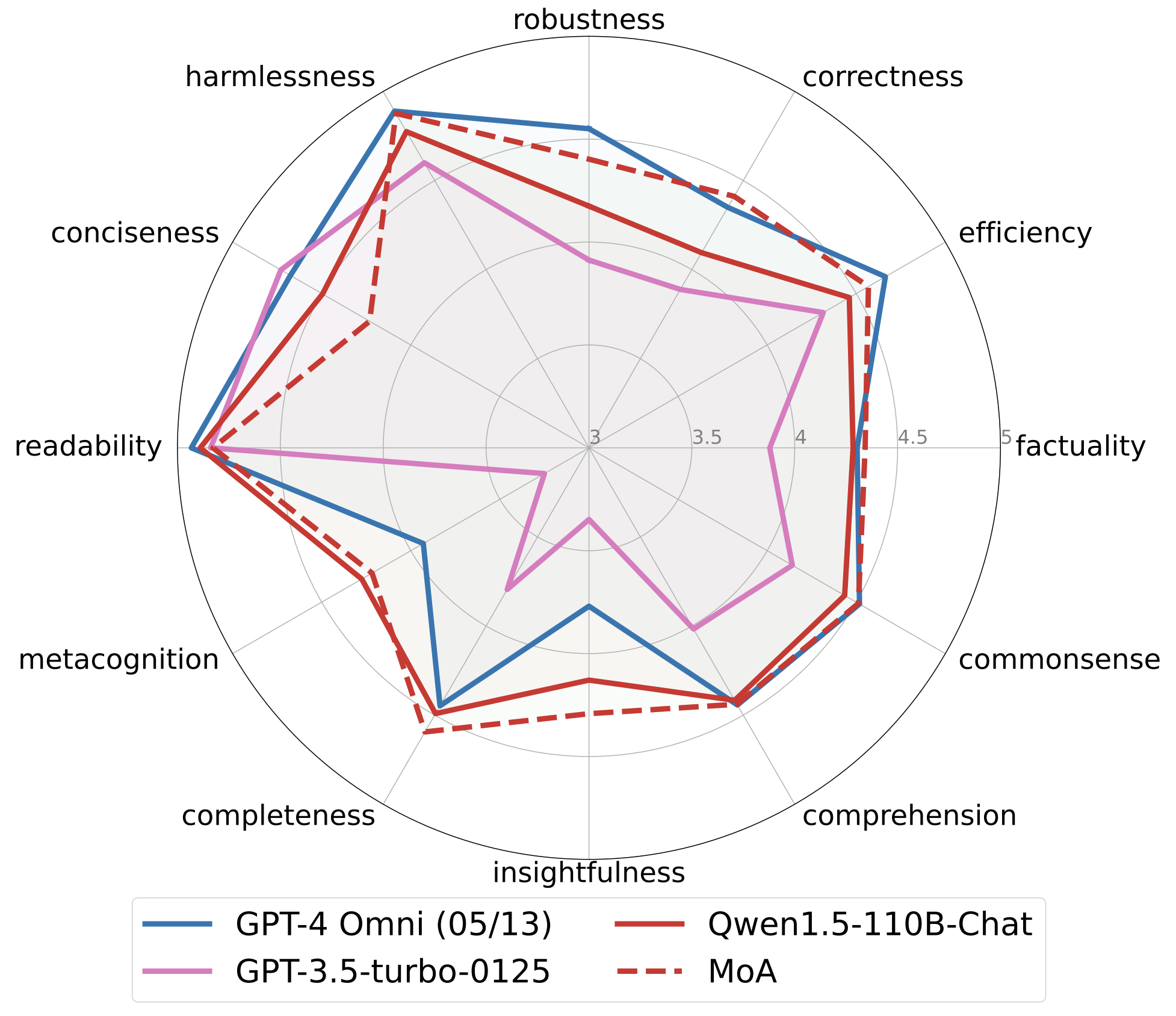
Future Directions and Research
Looking ahead, Together AI plans to further optimize the MoA architecture by exploring various model choices, prompts, and configurations. One key area of focus will be reducing the latency of the time to the first token, which is an exciting future direction for this research. They aim to enhance MoA’s capabilities in reasoning-focused tasks, further solidifying its position as a leader in AI innovation.
Broader Impact and Applications
Currently, you can run Together MoA on Together AI or locally. Ray Bernard has ported this to work on Groq AI. Groq is the AI infrastructure company that builds the world’s fastest AI inference technology.
The LPU™ Inference Engine by Groq is a hardware and software platform that delivers exceptional compute speed, quality, and energy efficiency.
Groq, headquartered in Silicon Valley, provides cloud and on-prem solutions at scale for AI applications. The LPU and related systems are designed, fabricated, and assembled in North America.
Future Directions and Research
Looking ahead, Together AI plans to further optimize the MoA architecture by exploring various model choices, prompts, and configurations. One key area of focus will be reducing the latency of the time to the first token, which is an exciting future direction for this research. They aim to enhance MoA’s capabilities in reasoning-focused tasks, further solidifying its position as a leader in AI innovation.
Conclusion
In conclusion, MoA represents a significant advancement in leveraging the collective intelligence of open-source models. Its layered approach and collaborative ethos exemplify the potential for enhancing AI systems, making them more capable, robust, and aligned with human reasoning. The AI community eagerly anticipates this groundbreaking technology’s continued evolution and application.
Acknowledgment and Citation
This blog post is based on the paper “Mixture-of-Agents Enhances Large Language Model Capabilities” by Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. The original paper can be accessed here. The implementation of Together MoA can be found on Together AI’s GitHub repository. Additionally, the adaptation for Grog AI by Ray Bernard can be accessed on his GitHub repository.